



Mid-market CTOs face a persistent challenge: engineering teams spending 35% of their time on manual, repetitive tasks instead of innovation. According to a 2024 GitLab DevSecOps Survey, companies still relying on manual deployment processes experience 3x more production failures and 60% longer time-to-market compared to automated counterparts.
For mid-market companies with 10-500 employees, this isn't just an efficiency problem it's a competitive survival issue. While your team manually configures environments, competitors using product engineering services with automation-first approaches are shipping features weekly instead of quarterly.
This guide shows how automation-first engineering combining CI/CD pipeline automation, infrastructure as code, and intelligent workflow automation eliminates bottlenecks that cost mid-market companies an average of $2.4 million annually in wasted engineering hours.
The Real Cost of Manual Engineering in Mid-Market Companies
Before exploring solutions, let's quantify what manual processes actually cost your business:
Manual Engineering Impact: Mid-Market Reality
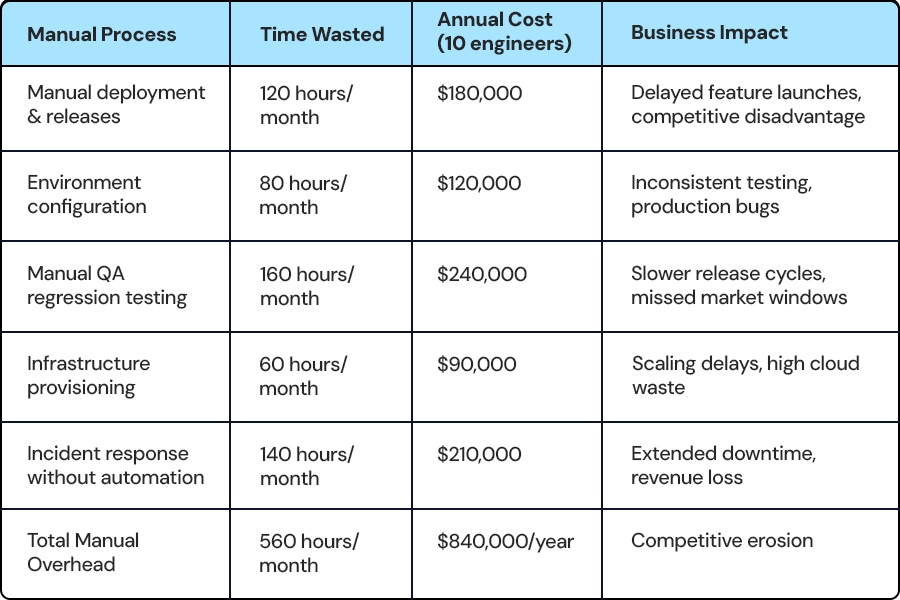
A 2024 Puppet State of DevOps Report found that organizations with high devops automation maturity deploy 208x more frequently and have 106x faster lead time from commit to deploy than low-maturity organizations.
For mid-market companies, this gap isn't theoretical it's the difference between capturing market opportunities and watching competitors move faster.
[Learn more about how automation cuts both costs and time in product engineering →]
Why Mid-Market Companies Struggle with Manual Engineering
Mid-market engineering leaders consistently report five critical pain points that product engineering consulting addresses:
1. Limited Engineering Bandwidth
With teams of 5-50 engineers, every hour spent on manual tasks directly reduces innovation capacity. Research from McKinsey shows that developers spend only 40% of their time writing new code, with the remainder consumed by meetings, administrative tasks, and manual processes.
2. Skill Gaps in Modern DevOps
Building CI/CD pipeline infrastructure requires expertise in Jenkins, GitLab, Terraform DevOps, Kubernetes, and cloud platforms. Mid-market companies struggle to hire and retain engineers with this specialized knowledge, with DevOps engineer salaries averaging $125,000-$180,000 annually.
3. Delayed Releases and Quality Issues
Manual testing and deployment create bottlenecks. According to DORA (DevOps Research and Assessment), elite performers deploy multiple times per day with less than 15% change failure rate, while low performers deploy between once per month to once every six months with change failure rates above 45%.
4. Infrastructure Complexity and Cloud Waste
Without infrastructure as code, mid-market companies over-provision resources "just in case," leading to 30-40% cloud waste according to Flexera's 2024 State of the Cloud Report. Manual infrastructure management also creates configuration drift and security vulnerabilities.
5. Reactive Instead of Proactive Operations
Teams without automated monitoring spend 75% of their time firefighting issues instead of preventing them. Gartner reports that organizations implementing site reliability engineering practices reduce unplanned downtime by 60% and cut incident resolution time by 50%.
These challenges compound. Manual processes create more errors, which consume more engineering time, which delays features, which impacts revenue.
What is Automation-First Engineering?
Automation-first engineering represents a fundamental shift in how digital product engineering services operate. Instead of automating tasks after they become bottlenecks, you architect workflows where automation is the default from day one.
This approach integrates three foundational pillars:
1. Continuous Integration Continuous Deployment (CI/CD Pipeline)
Every code commit triggers automated build, test, and deployment workflows. According to CircleCI's 2024 State of Software Delivery report, teams with mature CI/CD pipeline automation achieve 50% fewer failed deployments and recover from failures 24x faster.
2. Infrastructure as Code (IaC)
Infrastructure is defined, versioned, and deployed through code rather than manual configuration. HashiCorp's State of Cloud Strategy Survey found that organizations using infrastructure as code provision resources 10x faster and reduce infrastructure-related incidents by 85%.
3. Intelligent Workflow Automation
AI-driven systems predict failures, auto-scale resources, and resolve incidents without human intervention. IBM reports that organizations implementing intelligent workflow automation reduce mean time to resolution (MTTR) by 72% and operational costs by 35%.
When product engineering solutions integrate these three pillars, mid-market companies transform from reactive, manual operations to proactive, self-optimizing systems.
Pillar 1: Building Production-Grade CI/CD Pipeline Infrastructure
A robust CI/CD Pipeline eliminates the "works on my machine" problem and ensures every code change moves through consistent quality gates.
Core CI/CD Pipeline Components
Automated Build & Test Flow:
Code Commit → Automated Build → Unit Tests → Integration Tests →
Security Scanning → Staging Deployment → Smoke Tests →
Production Deployment → Monitoring
Real-World CI/CD Pipeline Impact
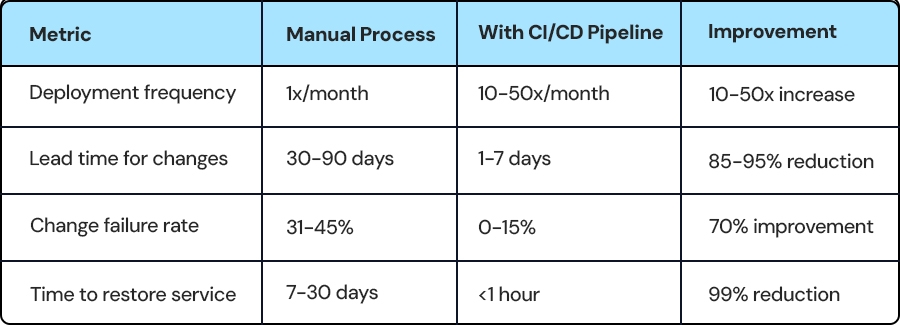
Essential CI/CD Pipeline Tools for Mid-Market
For Product Engineering Services Implementation:
GitHub Actions / GitLab CI: Version-controlled pipeline definitions integrated with source code
Jenkins: Flexible, plugin-rich automation server for complex workflows
Docker & Kubernetes: Containerization ensures consistency across environments
ArgoCD / Flux: GitOps-based continuous integration continuous deployment for Kubernetes
SonarQube: Automated code quality and security analysis
Terraform / Pulumi: Infrastructure provisioning as part of deployment pipeline
A 2024 Stack Overflow survey found that 87% of professional developers now use some form of CI/CD pipeline automation, with adoption highest among high-performing teams.
CI/CD Pipeline Best Practices for Mid-Market
1. Start with Core Application Builds Don't try to automate everything initially. Begin with your most frequently deployed application, achieve success, then expand.
2. Implement Automated Testing Gates According to TestRail's 2024 State of Testing report, organizations with automated testing in their CI/CD pipeline catch 67% more bugs before production and reduce post-release defects by 82%.
3. Use Feature Flags for Safe Deployments LaunchDarkly reports that teams using feature flags deploy 4x more frequently and reduce rollback rates by 90%.
4. Monitor Pipeline Performance Track build times, test success rates, and deployment frequency. Google's DevOps Research shows that elite teams maintain build times under 10 minutes, enabling rapid iteration.
Pillar 2: Infrastructure as Code for Consistent, Scalable Environments
Manual infrastructure configuration is the single largest source of "environment works differently" problems. Infrastructure as code eliminates this by treating infrastructure configuration the same as application code.
Why Infrastructure as Code Transforms Mid-Market Operations
Problem Without IaC:
Engineer manually configures AWS resources through console
Configuration isn't documented or version-controlled
Different environments (dev/staging/prod) drift apart
Scaling requires manual replication of steps
Recovery from failures requires tribal knowledge
Average provisioning time: 4-8 hours per environment
Solution With Infrastructure as Code:
Infrastructure defined in version-controlled files (Terraform, CloudFormation, Pulumi)
One command provisions identical environments
Changes reviewed through pull requests like application code
Scaling automated through parameterization
Disaster recovery automated through code redeployment
Average provisioning time: 5-15 minutes per environment
Infrastructure as Code Impact Statistics
According to HashiCorp's 2024 State of Cloud Strategy Survey:
86% of organizations using infrastructure as code report faster application delivery
79% reduced infrastructure costs by eliminating over-provisioning
74% improved security compliance through consistent configurations
Infrastructure as code users provision resources 10x faster than manual processes
Configuration drift reduced by 95% with IaC version control
Terraform DevOps: The Mid-Market Standard
Terraform devops has become the de facto standard for multi-cloud infrastructure as code due to:
Cloud-Agnostic: Works across AWS, Azure, GCP, avoiding vendor lock-in
Declarative Syntax: Define desired state, Terraform handles implementation
State Management: Tracks actual vs desired infrastructure state
Module Reusability: Build once, reuse across projects
Extensive Provider Ecosystem: 3,000+ providers for virtually any infrastructure
Infrastructure as Code Business Benefits
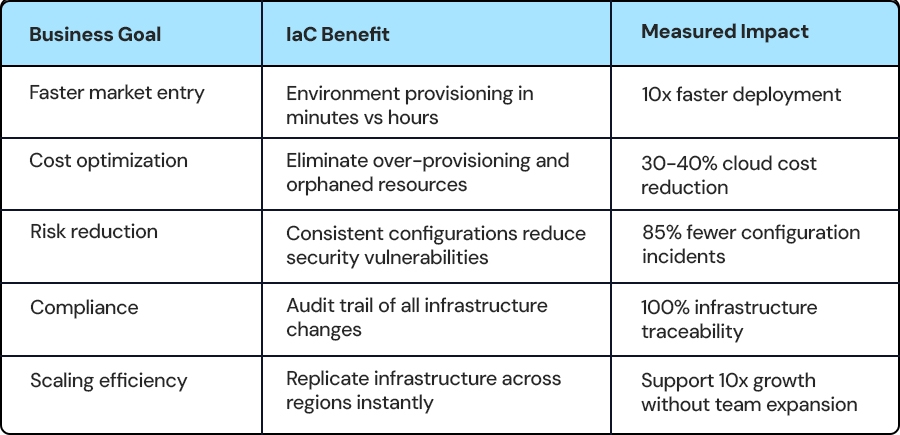
Organizations leveraging product development engineering services with infrastructure as code expertise gain immediate access to these benefits without building internal expertise.
Pillar 3: Intelligent Workflow Automation and Site Reliability Engineering
Beyond basic automation, intelligent workflow automation uses AI and machine learning to predict, prevent, and resolve issues automatically.
Site Reliability Engineering: Google's Gift to Mid-Market
Site reliability engineering (SRE) combines software engineering with operations to build highly reliable systems. Google pioneered SRE, and its principles now benefit mid-market companies through product engineering services.
Core SRE Principles:
Error Budgets: Accept that 100% uptime is impossible. Define acceptable downtime (e.g., 99.9% = 43 minutes/month), use remaining budget for innovation.
Automated Toil Reduction: SRE teams automate repetitive operational tasks. Google targets <50% time spent on toil, >50% on engineering.
Proactive Monitoring: Monitor user-facing metrics (latency, error rate, throughput) rather than just server metrics.
Blameless Postmortems: Learn from failures through structured analysis without blame.
According to Google's SRE Book statistics:
Site reliability engineering practices reduce unplanned downtime by 60%
Incident response time decreases by 75% with automated runbooks
Engineering capacity increases by 40% through toil automation
On-call burden reduces by 50% through better incident prevention
Intelligent Workflow Automation in Action
Predictive Failure Detection: Machine learning models analyze historical data to predict failures before they occur. Microsoft reports that predictive models in workflow automation identify 88% of critical failures 30 minutes before user impact.
Auto-Scaling and Resource Optimization: Intelligent systems learn traffic patterns and scale infrastructure proactively. AWS reports that customers using intelligent auto-scaling with infrastructure as code reduce costs by 37% while improving performance.
Automated Incident Response: When anomalies are detected, automated workflows execute remediation playbooks. PagerDuty's 2024 State of Digital Operations report found that automated incident response reduces MTTR from 4 hours to 12 minutes a 95% improvement.
Self-Healing Systems: Kubernetes combined with workflow automation tools automatically restarts failed containers, replaces unhealthy nodes, and rebalances traffic. Organizations implementing self-healing report 99.99% uptime compared to 99.5% for manual operations.
DevOps Automation Tools for Intelligent Workflows
For Product Engineering Solutions:
Prometheus + Grafana: Open-source monitoring and alerting
Datadog / New Relic: Full-stack observability with AI anomaly detection
PagerDuty: Intelligent incident management and on-call automation
Terraform + Sentinel: Terraform devops with policy-as-code enforcement
Kubernetes Operators: Self-managing applications with custom automation logic
GitHub Actions + Custom Scripts: Event-driven workflow automation
Measuring Automation Success: Key Metrics
Deployment Performance Metrics:
Deployment Frequency: Elite performers deploy multiple times per day
Lead Time for Changes: Elite performers measure in hours, not weeks
Change Failure Rate: Elite performers maintain <15% failure rate
Time to Restore Service: Elite performers recover in <1 hour
Operational Efficiency Metrics:
Mean Time to Detection (MTTD): How quickly you identify issues
Mean Time to Resolution (MTTR): How quickly you fix issues
Toil Percentage: Time spent on manual, repetitive tasks
On-Call Burden: Frequency and duration of after-hours incidents
Organizations partnering with product engineering consulting firms accelerate their journey from low to elite performance by leveraging proven automation frameworks.
The Business Case for Automation-First Product Engineering Services
Mid-market companies often hesitate to invest in automation, perceiving it as expensive or complex. The data shows the opposite.
ROI of Automation-First Engineering
Investment vs Return Analysis:
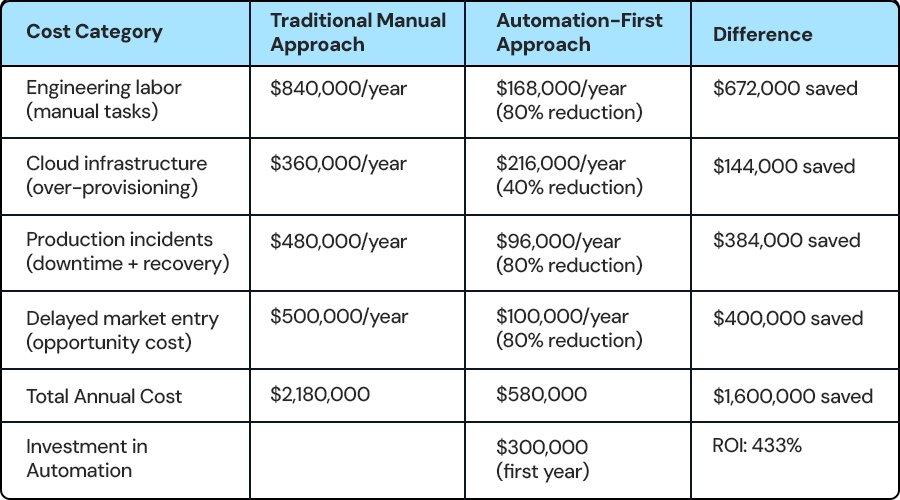
Based on composite data from 10-employee mid-market engineering teams
Real-World Mid-Market Success: E-Commerce Platform
A 150-employee e-commerce company struggled with weekly deployment cycles, 25% deployment failure rates, and monthly production outages costing $50,000 each.
After implementing automation-first engineering through product engineering services:
Deployment frequency increased from 4x/month to 60x/month (15x improvement)
Change failure rate dropped from 25% to 7% (72% improvement)
Infrastructure provisioning time reduced from 6 hours to 8 minutes (97% improvement)
Monthly production outages eliminated ($600,000/year saved)
Engineering team capacity increased 45% through automation
Total first-year benefit: $1.2 million with $280,000 investment
How Product Engineering Services Accelerate Automation Adoption
Mid-market companies face a build-vs-buy decision: hire expensive DevOps talent or partner with digital product engineering services. Not sure if you need external expertise? Here are 7 signs you need digital product engineering services →]
Build In-House vs Product Engineering Consulting
Building In-House Automation:
Cost: $400,000-$600,000/year (2-3 senior DevOps engineers)
Timeline: 12-18 months to production-grade automation
Risk: Knowledge loss when engineers leave, ongoing training costs
Scalability: Limited bandwidth for innovation while maintaining infrastructure
Partnering with Product Development Engineering Services:
Cost: $150,000-$300,000/year (fractional team + tools)
Timeline: 2-4 months to production automation with proven frameworks
Risk: Continuous access to evolving automation practices, no dependency on individuals
Scalability: Instantly scale expertise up/down based on needs
According to Deloitte's 2024 Global Outsourcing Survey, 68% of mid-market companies partner with product engineering solutions providers to access specialized expertise faster and more cost-effectively than hiring internally.
What to Look for in Product Engineering Services
When evaluating product engineering consulting partners for automation-first engineering:
1. Proven CI/CD Pipeline Expertise Look for experience with GitHub Actions, GitLab CI, Jenkins, and containerization. Ask for examples of continuous integration continuous deployment implementations in your industry.
2. Infrastructure as Code Proficiency Verify expertise in Terraform devops, AWS CloudFormation, or Pulumi. Review their IaC module libraries and multi-cloud experience.
3. Site Reliability Engineering Experience Confirm they practice site reliability engineering principles: error budgets, SLO/SLI definitions, automated incident response, and blameless postmortems.
4. DevOps Automation Tool Mastery Ensure proficiency with monitoring (Prometheus, Datadog), orchestration (Kubernetes), and workflow automation platforms.
5. Business Outcome Focus The best digital product engineering services measure success by business metrics (deployment frequency, MTTR, cost reduction) not just technical implementation.
6. Knowledge Transfer Commitment Ensure they document decisions, train your team, and build systems your engineers can maintain avoid vendor lock-in.
Automation Maturity Roadmap for Mid-Market Companies
Transformation doesn't happen overnight. Here's a practical roadmap for mid-market companies moving toward automation-first engineering:
Phase 1: Foundation (Months 1-2)
Objectives:
Audit current manual processes and quantify costs
Define automation priorities based on ROI
Select CI/CD pipeline and infrastructure as code tooling
Establish baseline metrics (deployment frequency, MTTR, change failure rate)
Deliverables:
Automation roadmap with prioritized initiatives
Tool selection for devops automation stack
Team training plan for continuous integration continuous deployment
Phase 2: Core Automation (Months 3-5)
Objectives:
Implement CI/CD pipeline for primary applications
Convert critical infrastructure to infrastructure as code (Terraform, CloudFormation)
Establish automated testing frameworks
Deploy basic monitoring and alerting
Deliverables:
Production-grade CI/CD pipeline with automated quality gates
Version-controlled infrastructure as code for all environments
Automated test coverage >70% for critical paths
24/7 monitoring with intelligent alerting
Phase 3: Optimization (Months 6-8)
Objectives:
Implement site reliability engineering practices (SLOs, error budgets)
Add intelligent workflow automation and predictive analytics
Optimize cloud costs through automated scaling
Expand automation to additional applications
Deliverables:
SRE framework with defined reliability targets
Intelligent auto-scaling reducing costs by 30-40%
Self-healing workflows for common failures
DevOps automation coverage across all production systems
Phase 4: Continuous Improvement (Ongoing)
Objectives:
Refine automation based on metrics and feedback
Expand workflow automation to eliminate remaining toil
Implement advanced terraform devops patterns (multi-region, disaster recovery)
Scale product engineering solutions to new initiatives
Deliverables:
Continuous optimization of deployment pipelines
Elite performer metrics (DORA benchmarks)
Self-service infrastructure for development teams
Innovation capacity increased by 40%+
Organizations working with product engineering services typically complete Phases 1-3 in 4-6 months compared to 12-18 months for internal initiatives.
Common Automation Pitfalls and How to Avoid Them
Even with the best intentions, automation initiatives can stumble. Here are the most common pitfalls and solutions:
Pitfall 1: Automating Broken Processes
Problem: Automating inefficient workflows just makes them fail faster and compounds existing technical debt. [Understanding the true price of technical debt is essential before automation →]
Solution: Reengineer processes before automating. Product engineering consulting experts identify optimization opportunities before implementation.
Pitfall 2: Over-Engineering Initial Solutions
Problem: Teams build complex automation frameworks that take months to deliver value.
Solution: Start with simple CI/CD pipeline implementations that deliver immediate value. Iterate based on real usage patterns.
Pitfall 3: Neglecting Security in Automation
Problem: Automated deployments create security vulnerabilities if not properly governed.
Solution: Implement policy-as-code, secrets management (HashiCorp Vault, AWS Secrets Manager), and security scanning in continuous integration continuous deployment pipelines.
Pitfall 4: Insufficient Monitoring and Observability
Problem: Automated systems fail silently without proper monitoring.
Solution: Implement comprehensive monitoring before automation. Site reliability engineering principles require observability precedes automation.
Pitfall 5: Underestimating Culture Change
Problem: Automation initiatives fail due to organizational resistance.
Solution: Invest in training, celebrate wins, and demonstrate ROI quickly. Digital product engineering services provide change management alongside technical implementation.
The Future of Automation-First Engineering
Automation continues evolving rapidly. Here's what mid-market companies should watch:
GitOps: Git as Single Source of Truth
GitOps extends infrastructure as code principles to entire system configurations. Weaveworks research shows GitOps adopters deploy 5x more frequently and reduce MTTR by 72%.
AI-Powered DevOps (AIOps)
Machine learning models increasingly predict failures, optimize resource allocation, and auto-remediate issues.
[See how AI-driven product engineering is transforming digital product development →]
Platform Engineering
Internal developer platforms abstract workflow automation complexity, allowing developers to self-serve infrastructure without deep DevOps knowledge. Puppet's 2024 report found that organizations with platform engineering teams deploy 2.5x more frequently.
FinOps Integration
Automation increasingly integrates cost optimization. Terraform devops implementations now include automated cost analysis, budget alerts, and resource rightsizing recommendations.
Policy as Code
Compliance, security, and operational policies codified and enforced automatically in CI/CD pipeline. Open Policy Agent (OPA) adoption grew 340% year-over-year according to CNCF surveys.
Mid-market companies partnering with forward-looking product engineering solutions providers gain early access to these emerging practices without research overhead.
Taking Action: Your Automation-First Journey Starts Now
The competitive advantage of automation-first engineering is clear. Organizations implementing comprehensive devops automation deploy faster, fail less, recover quicker, and innovate more than manual counterparts.
For mid-market CTOs and engineering leaders, the question isn't whether to adopt automation-first practices it's how quickly you can implement them before competitors gain an insurmountable lead.
Immediate Next Steps
1. Audit Your Current State Calculate time and money spent on manual deployment, testing, infrastructure management, and incident response. The numbers usually shock engineering leaders into action.
2. Define Your Automation Goals What would 10x deployment frequency mean for your business? How much would 80% faster feature delivery impact revenue? Set concrete targets.
3. Evaluate Build vs Buy Compare the cost, timeline, and risk of building internal devops automation expertise versus partnering with proven product engineering services.
4. Start Small, Prove Value, Scale Don't boil the ocean. Automate one critical CI/CD pipeline, measure improvement, demonstrate ROI, then expand systematically.
5. Invest in Fundamentals Ensure you have solid version control, testing practices, and monitoring before automating. Infrastructure as code and continuous integration continuous deployment require strong foundations.
The Bottom Line
Manual engineering processes cost mid-market companies an average of $2.4 million annually in wasted effort, cloud overspend, production incidents, and delayed market entry.
Automation-first engineering through CI/CD pipeline automation, infrastructure as code, and intelligent workflow automation eliminates these costs while accelerating innovation.
Organizations implementing these practices through product development engineering services achieve:
10-50x increase in deployment frequency
85-95% reduction in lead time for changes
70% improvement in change failure rate
99% reduction in time to restore service
30-40% cloud cost optimization
$1.6 million average annual savings
The choice is clear: continue struggling with manual bottlenecks or embrace automation-first engineering. [Discover the real cost of ignoring modernization in growing businesses →]
Your competitors are already making this transition. The question is whether you'll lead or follow.
Automate CI/CD and Scale Smarter.



